[CTL-ALT-DEL] sistema operativo da montare
Sabato 10 ero all’Ikea di Carugate, e mentre prendevamo il caffè Anna mi ha fatto notare che mi ero posizionato sotto questo monitor che aveva una grossa crisi. Vabbè, almeno ho imparato che cosa è dracut

Sabato 10 ero all’Ikea di Carugate, e mentre prendevamo il caffè Anna mi ha fatto notare che mi ero posizionato sotto questo monitor che aveva una grossa crisi. Vabbè, almeno ho imparato che cosa è dracut
[Ogni tanto ho scritto qualcosa sul blog Al Tamburo Riparato, tipicamente riprendendo i personaggi del Mondo Disco. Un paio di settimane fa mi sono dimenticato di festeggiare il compleanno del blog – non che mi ricordi del compleanno dei miei blog, intendiamoci – e allora ho buttato giù un post di scuse sotto forma di racconto. Eccolo qua in copia]
– “Perché mi hai chiamato con così tanta urgenza da farmi lasciare l’ottava portata del pranzo, Stibbons?” Non sono molte le cose che possono fare davvero arrabbiare Mustrum Ridcully… beh, no, sono moltissime: ma sicuramente allontanarlo da una tavola imbandita è parecchio in alto nella lista.
– “Vede, Arcicancelliere, Hex si sta comportando in maniera strana…”
– “E ha interrotto il mio pranzo per questo? Quando mai quell’ammasso di formiche si è comportato in maniera NON strana?”
– “Hex ha sempre avuto intuizioni fenomenali, Arcicancelliere. Ci sono solo alcuni piccoli problemi di conversione dei risultati in forma comprensibile, ma…”
Ponder Stibbons si ferma di colpo. Prende la striscia di carta appena prodotta da Hex, e la legge in silenzio: +++OUT OF CHEESE ERROR+++ “Quasi sempre, diciamo. Però stavolta è diverso, glielo assicuro! Guardi qua.” La striscia successiva riportava una scritta apparentemente meno insensata, soprattutto da quando una forma di formaggio del Chalk era stata aggiunta alla struttura dell’elaboratore: +++ DATE MISSING - RETURN BACK TO THE PAST? YES/NO/I AM HUNGRY+++
Ridcully strappa la nuova striscia dalle mani del giovane mago, dà una rapida occhiata e gliela restituisce grugnendo “Visto? Persino Hex segnala di aver fame. Ora posso tornare a tavola? A minuti sarà servito lo spuntino pre-merenda”.
– “Il punto è questo! Sono nove giorni che Hex ripete questo messaggio! All’inizio succedeva una volta al giorno, ma ormai ne compare uno all’ora. Pare che ci sia stato un problema nel tessuto dello spaziotempo e si sia perso un giorno. Dobbiamo fare qualcosa?”
– “E perché mai? Avere un giorno in meno ci ringiovanisce solo, non trovi?”
Stibbons pensò freneticamente a una risposta convincente. “Sì, però in questo modo si sono persi almeno quattro pasti…”
Ridcully si fermò di colpo. “In effetti, ora che mi ci fai pensare, forse è meglio rattoppare il tessuto spaziotemporale. Non vorrei che questa storia in futuro peggiorasse. Immagino che tu abbia già un’idea, vero?”
– “Beh, sì. Applicando un campo taumico sufficiente a un ottagono di clessidre, è possibile inserire un nuovo… no, un VECCHIO giorno eventualmente saltato nel computo del tempo. Mi sono permesso di approntare l’attrezzatura, ma naturalmente occorre il suo ok e soprattutto le sue capacità magiche per la sua attivazione.”
– “D’accordo, d’accordo. Ma non immediatamente. Terminato lo spuntino pre-merenda ci dovrebbe essere una mezz’oretta di tempo. Aspettami qua”.
Con una rapidità non del tutto imprevedibile, Ridcully sparì dall’Edificio per le Alte Energie Magiche per ritornare un’oretta dopo, con un tovagliolo al collo, la bacchetta in una mano, un cosciotto d’agnello nell’altra e il Bibliotecario al fianco. “Eccomi qua”, bofonchia a bocca piena”. “Ho fatto fare dei controlli al Bibliotecario e in effetti il 6 Grune non pare essersi appalesato nel calendario, il che è un problema visto che è il Giorno Del Grande Banchetto Continuo. Anzi, mi stupisco di non essermene accorto: non deve essere stata usata magia. Per fortuna esiste un incantesimo apposito”
– “Oook!” Il Bibliotecario assentì, aprendo con le zampe posteriori un libro riccamente istoriato intitolato Mille E Una Scusa Per Anniversari Dimenticati.
Ridcully posa la bacchetta e brandendo il cosciotto comincia a pronunciare le parole dell’incantesimo. Un soffio prima freddo e poi caldo percorre tutto l’edificio; le forme traballano un po’ per poi ricomporsi quasi uguali a prima, con la notevole eccezione delle otto clessidre che si sono tramutate in una sola. All’ultima parola il silenzio che era calato tutto intorno si rompe, le formiche in Hex cominciano a far girare la ruota a una velocità mai vista, e una nuova striscia di pergamena viene composta. Stibbons e Ridcully corrono a leggerla, mentre il Bibliotecario si mangia una banana: +++DATE RESTORED - SYXTH OF GRUNE - HAPPY BIRTHDAY, TAMBURO RIPARATO!!!+++
 Ero fermo al semaforo, e mi sono trovato davanti questo barbiere/parrucchiere. La qualità della foto è quel che è, perché temevo scattasse il verde… (non che ci fossero auto dietro di me, ma il concetto era quello)
Ero fermo al semaforo, e mi sono trovato davanti questo barbiere/parrucchiere. La qualità della foto è quel che è, perché temevo scattasse il verde… (non che ci fossero auto dietro di me, ma il concetto era quello)
foto scattata il 13 luglio a Cuveglio (VA)

Vi siete mai chiesti quale sia il sistema operativo che gestisce le biglietterie automatiche ATM? Stamattina finalmente l’ho scoperto. Non arrivano nemmeno a Windows XP 🙂 D’altra parte se le Carrelli sono tranquillamente in circolazione da novant’anni che cosa volete che siano due decenni?
foto scattata il 4 luglio 2019 alla stazione metropolitana Affori Nord
Ho deciso di leggere l’ultimo libro di Baricco. Avevo saltato I barbari, esattamente come ho saltato tutta la sua produzione editoriale. In realtà leggevo la rubrica che teneva sulla Stampa qualche decennio fa, e ai tempi avevo stabilito che mi era bastata questa esposizione. Succede però che il tema di The Game si intreccia con altre cose su cui sto cercando di trovare una quadra. È vero che “ars longa, vita brevis”, come diceva (in greco) Ippocrate e dice (in latino) Douglas Hofstadter; però è anche vero che non è bello eliminare pregiudizialmente qualcosa, e quindi ho pensato di dedicare qualche ora della mia vita a vedere come Baricco ha voluto trattare il tema. (Spoiler: pensavo molto peggio. Non consiglierei il libro come unica voce in capitolo, ma vale la pena di leggerlo se si ha già un’idea di quello di cui si parla: se lo si prende senza preconcetti, si scopre che non tutto quello che diamo per scontato è vero).
Qui però non voglio parlare tanto del contenuto del libro – una mia recensione più o meno decente la trovate qua – quanto piuttosto della “baricchitudine”. Mi interessa insomma raccontare come io ho decodificato il suo pensiero, perché ci sono varie cose che secondo me rimangono nascoste. Per prima cosa, Baricco scrive dannatamente bene. Su questo non c’è storia. Le sue frasi si snocciolano senza sforzo, e il lettore plana amabilmente su di esse senza sforzo alcuno. (Sono molto invidioso, sì). Questo è bellissimo, ma nel caso di un saggio c’è un piccolo problema: il lettore in questione si beve tutto senza porsi alcuna domanda sulla verità di quanto scritto. Come sappiamo bene, una bugia ben proposta funziona meglio di una verità nuda e cruda. Sto dicendo che Baricco ha scritto una serie di fregnacce? No. Ne ha scritte, intendiamoci: ma andando avanti nella lettura mi sono accorto che spesso – qualche decina di pagine dopo quello che avevo rubricato come cazzata – Baricco scriveva esattamente l’opposto. L’idea che mi sono fatto è che è una palla che lui abbia scritto il libro buttando giù man mano il testo. Lì dietro c’è un lavoraccio, e la cosa mi fa incavolare ancora di più, perché sono convinto che lui abbia messo apposta buona parte degli erroracci per far fare al lettore il giro che lui voleva. Non è bello. Verso la fine lo ammette anche tra le righe, anche se non ha il coraggio di dire che i primi due capitoli sono in buona parte fregnacce e se ne esce con “è preistoria” con il consiglio di non rileggere quel testo.
Baricco è un filosofo: quindi per lui il Game ha una filosofia sottostante. Io non sono filosofo e anzi sono sempre stato una capra in filosofia: però non mi bevo il suo professarsi cartesiano con tanto di esempi, e preferisco fermarmi alla lettera. Il Game è Movimento – lo dice lui – quindi è eracliteo. Il problema è che se si parte da questo assunto occorre portarlo avanti coerentemente, cosa che Baricco del resto fa. Questo va benissimo quando concludi che la caratteristica fondamentale di questi “oltremondi” digitali sia la velocità e la leggerezza, che fanno portare a galla l’essenza delle cose anziché nasconderla in fondo come fa il nostro mondo analogico. (“Analogico” e “digitale” sono traduzioni mie, Baricco non usa mai questa terminologia, e anche questo secondo me è un segno: vuole spostare il terreno di gioco, e per farlo coglie una caratteristica diversa da quella tipicamente usata. Ottima mossa, perché costringe il lettore a rivedere tutti i suoi pre-giudizi). Questo però va molto meno bene quando decide di rinominare la post-verità “verità-veloce”, definendola come «una verità che per salire alla superficie del mondo – cioè per diventare comprensibile ai piú e per essere rilevata dall’attenzione della gente – si ridisegna in modo aerodinamico perdendo per strada esattezza e precisione e guadagnando però in sintesi e velocità». Baricco scrive molto meglio di me, ma il concetto è lo stesso che ho scritto nel capoverso precedente: «una bugia ben proposta funziona meglio di una verità nuda e cruda». L’esempio che fa, quello dei “vinili che hanno venduto più del digitale”, è paradigmatico: usa varie pagine per mostrare come quell’affermazione sia l’equivalente delle barzellette su Radio Erevan, perché quello che è successo è che nel Regno Unito in una specifica settimana le vendite di vinile hanno superato il fatturato della pubblicità collegata al download gratuito in digitale, e conclude che sì, la frase non rappresenta i fatti, ma permette però di scoprire tante cose. Palle. Le cose le scopri solo se stai ancora pensando come una persona pre-Game e vai a sfrucugliare. Anche la sua affermazione che in fin dei conti il termine “post-truth” esisteva già nei casi delle armi di distruzione di massa di Saddam Hussein e nel doping di Armstrong non funziona: nel secondo caso non è nemmeno post-verità ma semplice negazione, e ai tempi della scenetta di Colin Powell il termine era stato usato una sola volta dieci anni prima in un libro che non era stato filato praticamente da nessuno. (Il secondo libro, che aveva anche il termine nel titolo, uscì l’anno successivo, e fu comunque filato poco).
Questa difesa baricchiana della post-verità, che funziona indipendentemente dai fatti, ha ovviamente una sua origine ben precisa, che si riassume in una parola: narrazione. (“Storytelling”, se siete molto anglofoni. Però questo è uno dei pochi casi in cui il termine italiano è riuscito a mantenere una certa qual forza). Baricco è un campione di narrazione, per negarlo occorre avere davvero una bella faccia tosta. Ha anche ragione quando afferma che non è necessario partire dai fatti per ottenere una bella narrazione: millenni di epica dovrebbero averlo reso chiaro. Però non può incrociare i flussi e applicare al mondo gli stessi schemi di un oltremondo ante litteram qual è la narrativa! Ok, l’ha fatto, e sono ragionevolmente certo che giocasse sul fatto che non se ne sarebbe accorto nessuno, né tra i suoi fan che si sarebbero bevuti tutto né tra i detrattori che invece l’avrebbero stroncato a priori e quindi senza un vero confronto sul testo. Ecco: forse questa sì che è verità-veloce!
Un’ultima nota, tecnica ma anche personale. Baricco ha cinque anni più di me, quindi siamo praticamente della stessa generazione. Però abbiamo vissuto una vita diversissima. È vero che io non sono un nativo digitale, ma sono attaccato a una tastiera da quando avevo quindici anni: faccio quasi parte del gruppo dei pionieri del digitale – attenzione: non dell’élite di cui lui parla: al più, esagerando, dei tecnici nascosti dietro le quinte . Baricco ha fatto un bel lavoro per entrare “da vecchio” nell’oltremondo: ma qualcosa rimane sempre. Ho sorriso quando ho letto «È la postura in cui sto scrivendo questo libro. [Non quella in cui, probabilmente, lo state leggendo: onore al libro cartaceo, che ancora resiste a qualsiasi mutazione].» Stavo naturalmente leggendo il libro nella postura uomo-schermo, quello del furbofono dove ho la copia in formato ePub. Possiamo poi dibattere se la versione elettronica di questo libro sia o no una mutazione e se le note che ho preso sullo smartphone siano la stessa cosa di quelle che una volta si scrivevano a matita sulle pagine: però quell’inciso è la prova che forse non tutto è ancora così liscio come lui cerca di convincerci…
 Il sistema di predizione del Samsung Note9 ha indubbiamente dei problemi. Questo è un esempio che ho preparato apposta, ma garantisco che generalmente se sto scrivendo “un altro” o qualunque altra combinazione di un + parola che comincia con vocale lui è felicissimo di propormi la combinazione apostrofata.
Il sistema di predizione del Samsung Note9 ha indubbiamente dei problemi. Questo è un esempio che ho preparato apposta, ma garantisco che generalmente se sto scrivendo “un altro” o qualunque altra combinazione di un + parola che comincia con vocale lui è felicissimo di propormi la combinazione apostrofata.
Mi chiedo solo se è un enorme baco di programmazione oppure un esplicito tentativo di rendere ancora più ignorante la gente…
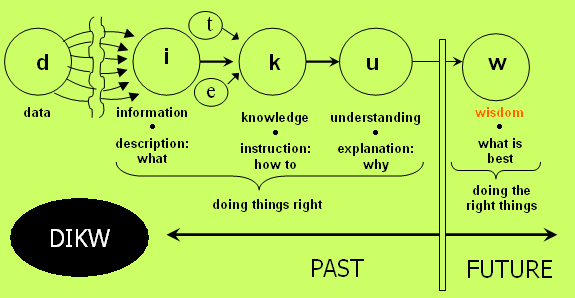
informazione e conoscenza non sono necessariamente correlate (da https://en.wikipedia.org/wiki/File:DIKW_(1).png )
C’è però un passaggio dell’articolo che a mio parere è molto più interessante per comprendere come l’intelligencija si ponga davanti alla cultura. Cito:
Sono questi gli effetti, anch’essi paradossali, dell’età dei social e di Wikipedia. La disponibilità immediata di informazioni a vantaggio di chiunque non ha portato, come si credeva, a un generale accrescimento della cultura e della capacità critica. Al contrario, ha favorito il conformismo e la chiusura intellettuale e ha reso disponibile non una conoscenza diffusa ma una nociva infarinatura un tanto al kilo.
Ecco. Una frase come quella mostra un fraintendimento tipico, di cui ho scritto con Paolo Artuso nel nostro Scimmie digitali. Perché mai avere più informazione dovrebbe portare a una maggiore cultura? Se la cosa vi pare sensata, provate a pensare alla quantità di informazione contenuta nei computer. Direste forse che essi siano acculturati? La piramide DIKW spiega molto bene il concetto. La conoscenza si basa sull’informazione, ma è separata da essa. Le informazioni sono i mattoni che noi dobbiamo prendere e assemblare per formare la nostra “casa della conoscenza”, più o meno sgarrupata a seconda delle nostre capacità e del materiale che troviamo. Ma i mattoni da soli non bastano: come minimo ci vuole della malta per tenerli insieme. Fuori di metafora, la malta è la nostra materia grigia che deve essere messa in moto per comprendere le informazioni che vediamo, confrontandole magari tra di loro per avere un’idea di quali probabilmente sono errate – per tutta una serie di ragioni, dal basarsi su dati errati all’essere state create apposta per confondere. Naturalmente azionare la materia grigia è sempre un’operazione costosa: semplicemente un tempo si tendeva a essere conformisti seguendo quello che diceva il prete o il segretario del partito, mentre adesso ci sono più conformismi tra i quali scegliere… no, il verbo “scegliere” non funziona bene, perché richiede comunque fatica. Meglio “prenderne uno”.
Quello che forse potremmo dire è un’altra cosa: che la generazione Wikipedia pensa di dover avere una propria opinione su tutto, cosa che in effetti in passato non capitava, o almeno non capitava pubblicamente. Ma anche su questo io ho dei dubbi. Mi pare che più che esprimere opinioni ci si limiti a rilanciare pedissequamente quello che si trova in giro e piace, dai gattini agli insulti contro Laura Boldrini, dalle frasi leziose in stile Baci Perugina alla foto della prima pagina del libro su Matteo Salvini. Non parlerei nemmeno di infarinatura di conoscenza, insomma: non si sta superando il livello “conoscenza”. Io sono pessimista e temo che dovremo convivere con questo nuovo modo di agire, ma in ogni caso la disponibilità o meno di informazioni è irrilevante in questo contesto. Cultura capacità critica, se proprio le volete, ve le dovete gestire da voi.
P.S.: L’articolo originale di Justin Kruger e David Dunning è del 1999: prima che nascesse Wikipedia, ma soprattutto prima che Internet diventasse così pervasiva. Non diamo proprio tutte le colpe alla rete.
 Non è che io capisca così bene a cosa servano queste pubblicità che arrivano direttamente dal cloud. Però se la prendi forse ogni tanto dovresti controllare se effettivamente i dati arrivano, no?
Non è che io capisca così bene a cosa servano queste pubblicità che arrivano direttamente dal cloud. Però se la prendi forse ogni tanto dovresti controllare se effettivamente i dati arrivano, no?
(Milano, Piazzale Istria, 12 maggio 2019)
Dal primo marzo Google eliminerà la sua app Inbox, con la scusa che le sue caratteristiche principali sono state inserite direttamente in Gmail. Non sono così d’accordo, e ho cercato di scoprire se si potesse mantenere la versione attuale almeno per un po’, lasciando però l’aggiornamento automatico delle altre app. Non so se funzionerà, ma la soluzione è relativamente semplice. Da Google Play si cerca l’app e si clicca sui tre puntini in alto a destra. Da lì basta togliere la spunta agli aggiornamenti automatici.

Stamattina ero in Centrale con Jacopo ad aspettare la metropolitana, e mi sono accorto che hanno rifatto la banda gialla con le indicazioni. Solo che chi ha scritto il testo era evidentemente un pessimo digitatore, un po’ come me. Mi chiedo solo se Forun faccia rima con terun …
foto scattata il 12 febbraio 2019
![[una schermata di Pong]](http://xmau.com/wp/archivi/wp-content/uploads/sites/2/2019/05/Pong.png)